一、页面入口
后台左侧菜单栏 →【应用】→插件【AI智能体】→ Token 消耗日志
作用:查看 AI 对话扣费、调用量、接口性能、账单核对,用来核算各大模型平台消耗费用。
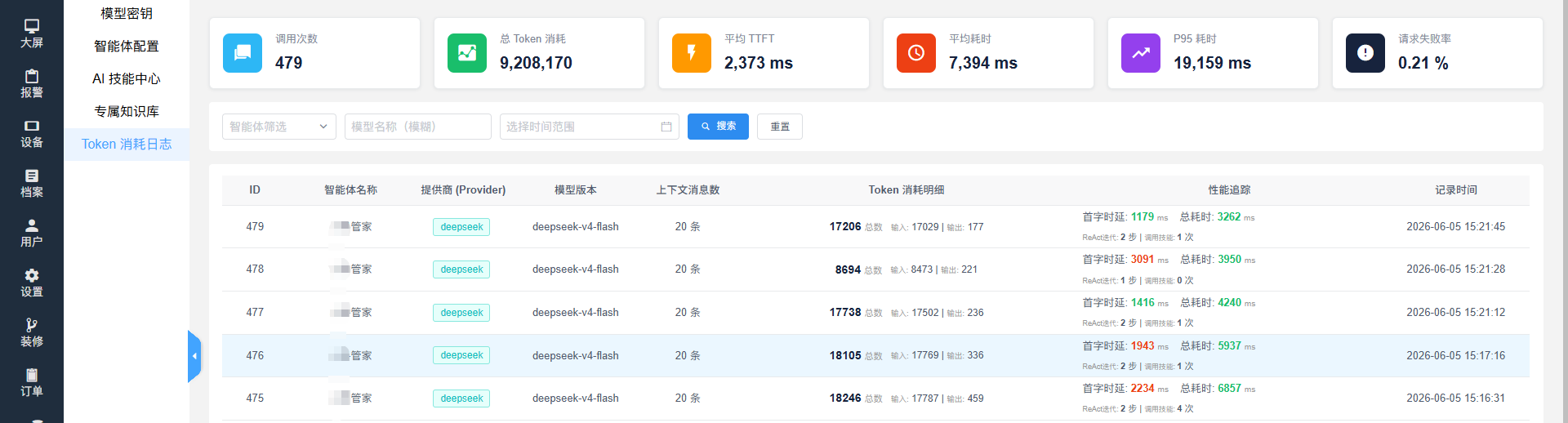
二、顶部统计卡片说明
| 统计项 | 释义 | 参考说明 |
|---|---|---|
| 调用次数 | AI 总对话轮次 | 平台用户和 AI 聊天总次数 |
| 总 Token 消耗 | 累计计费字符总量(输入 + 输出合计) | DeepSeek / 豆包 / 千问等厂商按 Token 计费,总量用来核算账单 |
| 平均 TTFT(首字时延) | 用户发消息→AI 吐出第一个字耗时 | 数值越小 AI 回复越快 |
| 平均耗时 | 单轮对话整体响应时长 | 数值偏高排查网络 / 中转 |
| P95 耗时 | 95% 的请求耗时低于该数值 | 用于判断接口稳定性 |
| 请求失败率 | AI 调用报错比例 | >5% 需要检查 API 密钥、账户余额 |
三、下方明细列表字段解释
| 列表字段 | 说明 |
|---|---|
| 智能体名称 | 哪个 AI 管家产生的对话(例:xx管家) |
| 提供商 | 对接的大模型厂商:DeepSeek / 豆包 / 千问等 |
| 模型版本 | 选用的模型型号(deepseek-v4-flash) |
| 上下文消息数 | 本轮对话携带历史聊天条数,条数越多输入 Token 越高、扣费越多 |
| Token 消耗明细 | 总数 = 输入 token + 输出 token; 输入:用户提问 + 知识库 + 档案 + 系统提示词占用字符(扣费大头) 输出:AI 回复内容字符 |
| 性能追踪 | 首字时延:AI 首词响应速度; 总耗时:整轮对话耗时; ReAct 迭代:AI 调用技能次数(查设备 / 档案 / 知识库就会计入迭代) |
| 记录时间 | 用户对话发生时间 |
四、筛选使用方法
智能体筛选:下拉单独查看某一个管家消耗;
模型名称:筛选 DeepSeek / 豆包等不同厂商数据;
选择时间范围:按日 / 按月导出对账,和大模型官网账单核对。
五、客户实用操作指南
1、对账核算
拿页面【总 Token 消耗】→对照 DeepSeek / 火山 / 阿里云后台账单,核对扣费是否一致。
常见 FAQ
- Q:为什么同是一轮对话,Token 消耗差距很大? A:携带历史聊天越多、调用档案 / 设备 / 知识库越多,输入 Token 越高;AI 回复越长,输出越高。
- Q:ReAct 迭代数字高代表什么? A:AI 多次调用技能(查健康档案、查手环告警、查知识库),迭代越多消耗越高。